Research study/2026-06-11
Computational prioritization of cysteine-rich secreted-like peptide candidates from psilocybin-producing fungal proteomes
A reproducible computational survey of cysteine-rich secreted-like peptide families across fungal proteomes
- Date
- 2026-06-11
- Study type
- Formal computational study
- Source
- Protean Psilocybe Secretome Campaign
Proteins analyzed
58,449
Mature candidates
470
70% families
346
Study boundary
This study is computational prioritization only. Secreted-like means sequence features consistent with a deterministic heuristic, not confirmed secretion. DBAASP and other local reference archives provide nearest-neighbor context only and do not establish activity, toxicity profile, molecular function, experimental validation, or global novelty for any Protean candidate.
Abstract
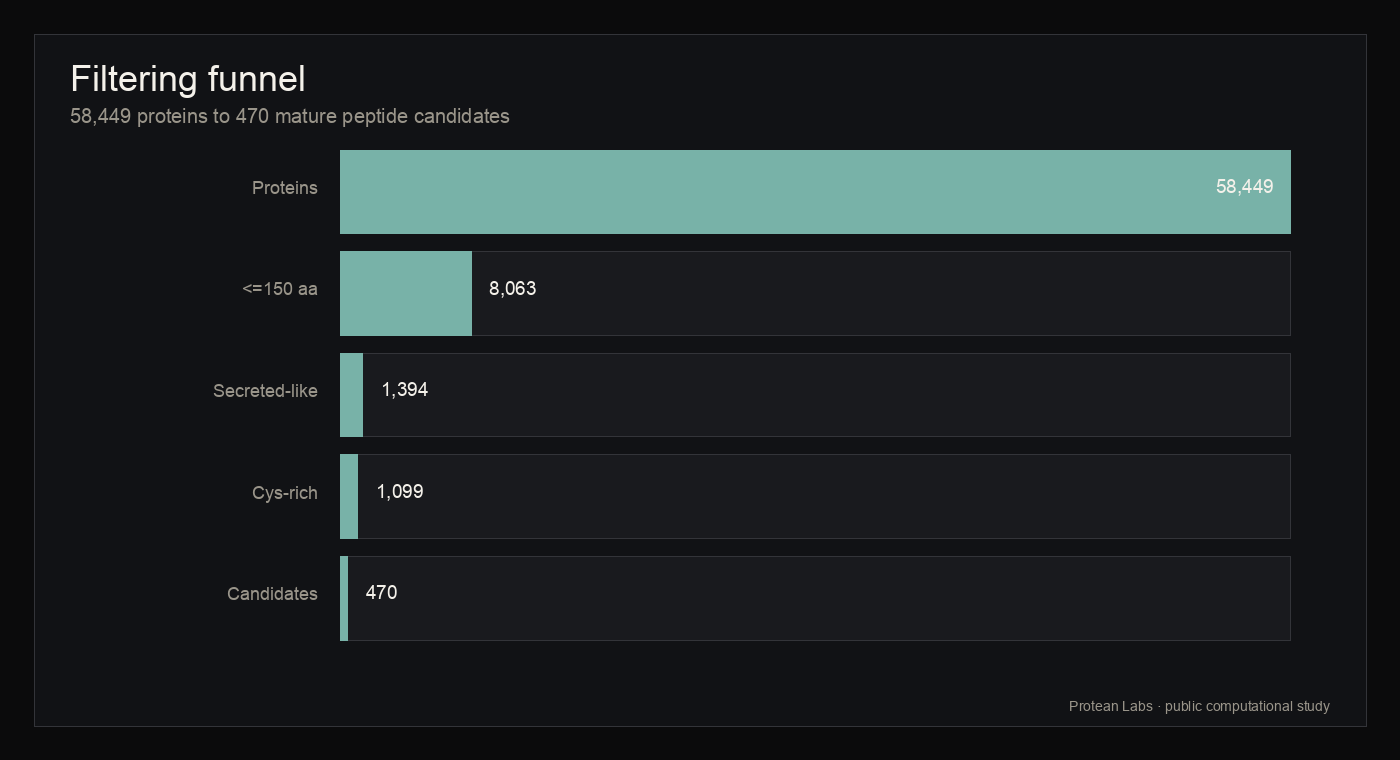
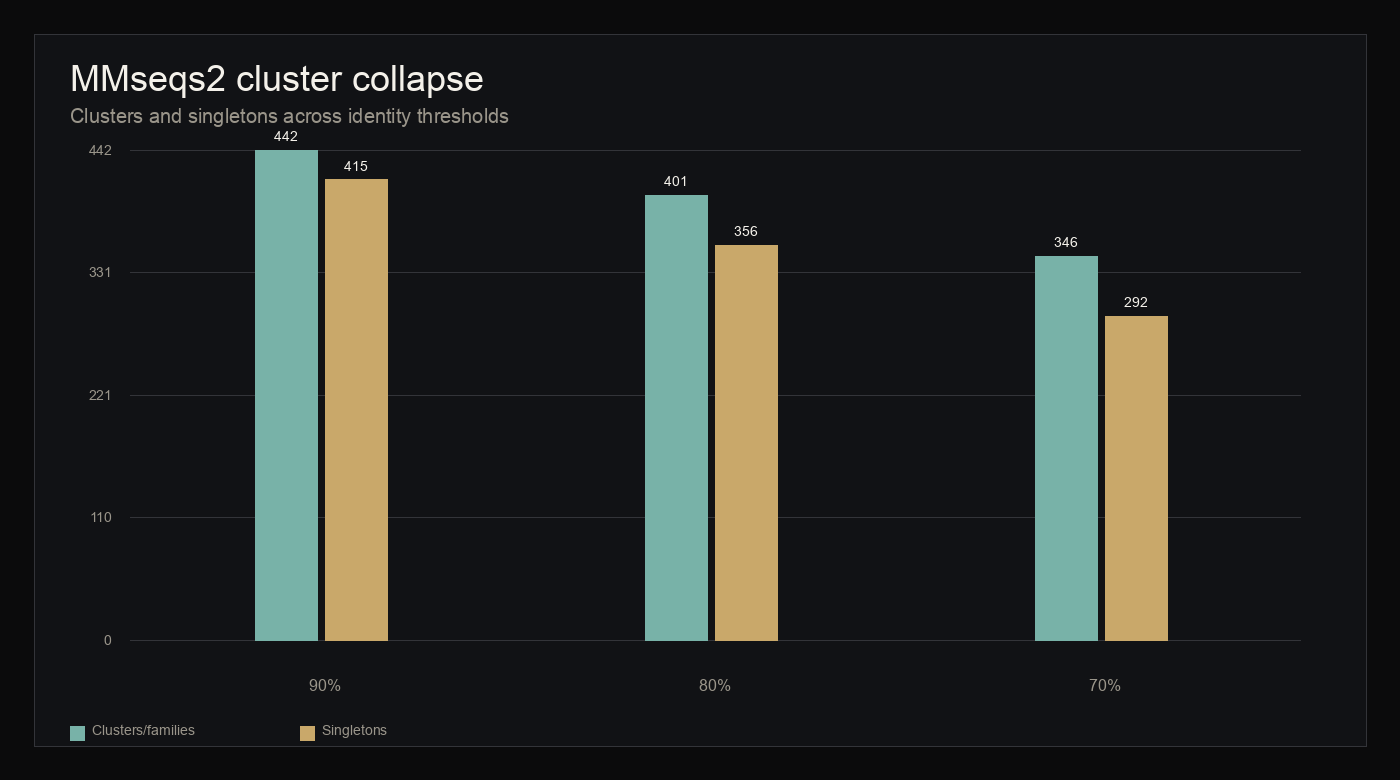
Psilocybin-producing fungi are primarily known for small-molecule biosynthesis, but their predicted proteomes also encode short peptide-like sequences that remain sparsely characterized. This study reports a reproducible computational survey of available fungal proteomes to identify short cysteine-rich, secreted-like peptide candidates. Protean analyzed 58,449 predicted proteins from four included fungal assemblies, retained 8,063 proteins of 150 amino acids or fewer, identified 1,394 secreted-like sequences by deterministic sequence heuristics, retained 1,099 cysteine-rich precursors, and produced 470 unique mature peptide candidates. Phase II family clustering resolved these candidates into 346 families at 70 percent identity and 0.8 coverage, including 292 singleton families and 24 cross-species families. Local reference-space comparison using acquired peptide archives, including a DBAASP snapshot used only for nearest-neighbor context, found no exact DBAASP matches and no candidate nearest neighbors at or above 90 percent identity. These results define a bounded computational map of cysteine-rich, secreted-like fungal peptide candidates for future scientific review. The study does not claim confirmed secretion, biological activity, therapeutic relevance, toxicity profile, global novelty, or experimental validation.
Plain-English Summary
What this study
means.
Protean screened public fungal proteomes for short, cysteine-rich peptide candidates with secreted-like sequence features. The campaign reduced tens of thousands of predicted proteins to a smaller set of mature peptide candidates, then grouped those candidates into sequence families so the result could be read as a family-level map instead of a raw candidate list.
This is computational prioritization only. The page identifies candidates and reference-space relationships for future scientific review; it does not show that any candidate is secreted in an organism, has biological activity, has a toxicity profile, or has been experimentally validated.
Key findings
- The workflow reduced 58,449 analyzed fungal proteins to 470 unique mature peptide candidates without rerunning discovery for this publication page.
- MMseqs2 family collapse yielded 346 primary families at 70 percent identity, showing that the set is not reducible to one repeated sequence motif.
- The largest 70 percent family contained 17 members; 322 families were species-specific and 24 families included more than one species.
- Recurring cysteine-spacing architectures included C7-1-33-13-6-1-13C in 16 families, C7-1-33-14-6-1-13C in 10 families, and C22-8-31C in 6 families.
- The DBAASP comparison used 25,069 raw records, 20,582 normalized rows, and 16,989 unique peptide sequences as local nearest-neighbor context only.
- No exact DBAASP matches and no candidate nearest neighbors at or above 90 percent identity were observed in the local DBAASP snapshot.
01
Introduction
Fungal proteomes encode many short proteins and peptide-like sequences whose biological roles are incompletely understood. In psilocybin-producing fungal lineages, public attention often centers on secondary metabolites, but predicted proteomes provide a separate computational substrate for asking whether short cysteine-rich, secreted-like peptide candidates are present across available assemblies.
This study frames those sequences as a reproducible sequence-space survey. It does not infer therapeutic relevance, biological activity, secretion, or risk profile from sequence alone. Instead, the goal is to create a transparent family-level map that can support future human scientific review.
02
Study Design
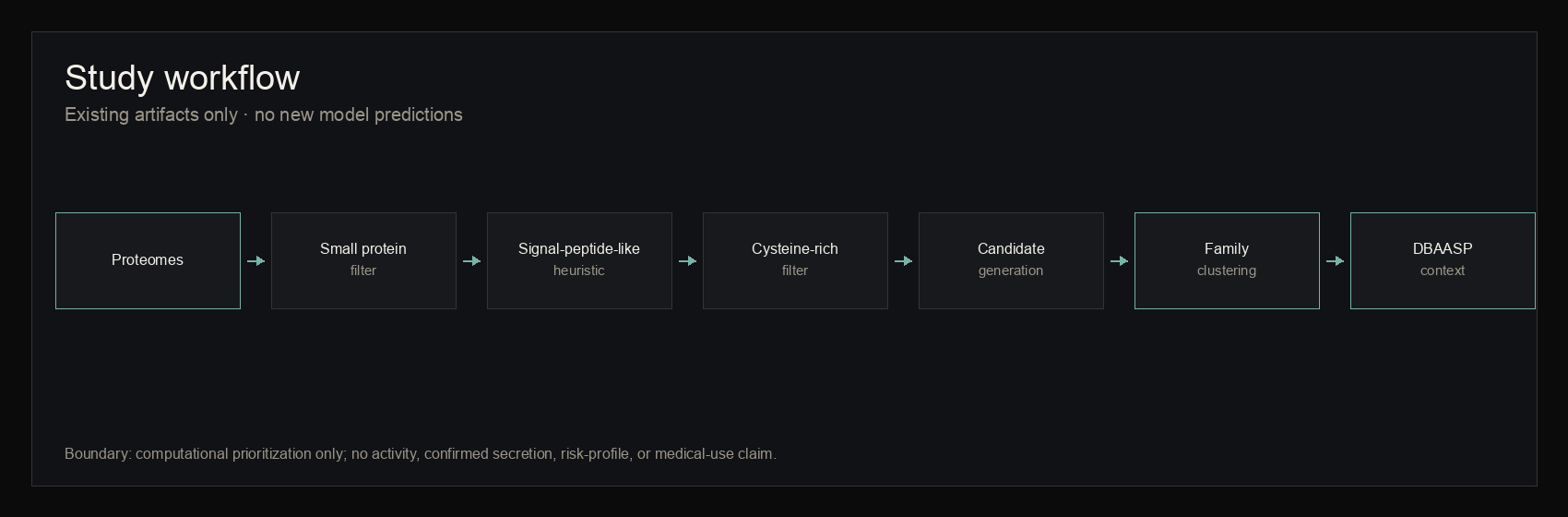
The study was built from existing Protean campaign artifacts. No discovery rerun, score mutation, rank mutation, scoring-weight change, validator change, or new model/tool prediction was performed for the website publication step.
The campaign followed a fixed flow: proteome acquisition, normalization, small-protein extraction, deterministic secreted-like prediction, mature peptide extraction, cysteine-rich filtering, deduplication, candidate generation, scoring, family collapse, and local reference comparison. Phase II shifted the interpretation from 470 individual candidates to a family-level view of redundancy, motifs, and reference-space context.
03
Data Sources
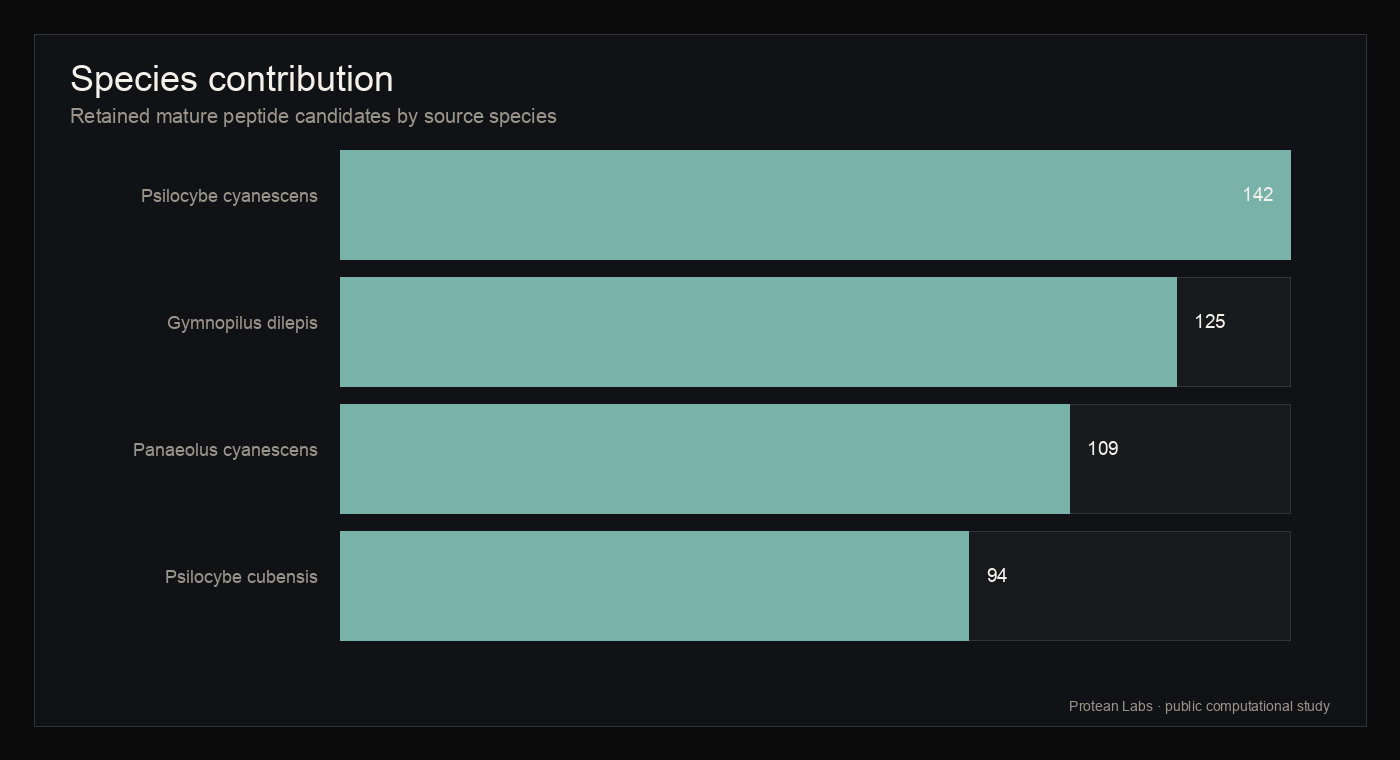
The acquisition phase selected four assemblies that exposed the required NCBI protein FASTA, genomic GFF, and assembly report files: Psilocybe cubensis, Psilocybe cyanescens, Panaeolus cyanescens, and Gymnopilus dilepis. Psilocybe azurescens and Pluteus salicinus were excluded because the acquisition manifest did not find a required protein FASTA plus genomic GFF package.
Reference-space comparison used the acquired local reference archive including DBAASP, DRAMP, APD, MEROPS, and PeptideAtlas where available. DBAASP was integrated as a local-first snapshot from dbaasp.org for nearest-neighbor retrieval, reference-space analysis, and annotation context only.
04
Computational Methods
FASTA records were normalized into source-tracked sequence objects and screened for short proteins of <=150 amino acids. Secreted-like status was assigned by deterministic sequence features including N-terminal hydrophobicity, positively charged N-region features, cleavage-motif heuristics, and transmembrane-risk checks.
Cysteine-rich precursors required mature peptide lengths from 20 to 150 amino acids and either at least four cysteine residues or a cysteine fraction of at least 0.06. Candidate properties, including cysteine count, cysteine fraction, spacing motif, charge, pI, hydrophobicity, aromatic fraction, glycine enrichment, proline enrichment, and protease-vulnerability proxy, were computed for prioritization context.
05
Candidate Generation
The campaign retained 470 mature peptide candidates after filtering and global deduplication. Candidate IDs, precursor sequences, mature sequences, species, source assembly, source database, computed features, and provenance were preserved in native Protean candidate objects.
The public study reports the existing candidate and family outputs. It does not modify the top-25 ranking, scoring stack, weights, validators, frontier behavior, or database-comparison effects.
06
Family Clustering
Phase II clustered mature peptide sequences with MMseqs2 version 18-8cc5c at 90, 80, and 70 percent identity. The 70 percent identity and 0.8 coverage threshold was used as the primary family definition.
At 70 percent identity, the 470 candidates collapsed into 346 families, including 292 singletons. The largest family contained 17 members. Species-specific families numbered 322, while 24 families included candidates from more than one species.
07
Reference Corpus Comparison
The DBAASP snapshot contained 25,069 raw records, 20,582 canonical normalized peptide rows, 16,989 unique peptide sequences, and 171 hydrated detail records. The snapshot was local-first and introduced no live scoring dependency.
Candidate-level DBAASP nearest-neighbor comparison found 0 exact matches, 0 matches at or above 90 percent identity, 4 matches at or above 80 percent identity, 26 at or above 70 percent identity, and 441 at or above 50 percent identity. The median nearest-neighbor identity was 0.5625 and the maximum was 0.875. DBAASP activity, toxicity, hemolysis, structure, and literature annotations, when present, describe nearest neighbors only and are not labels for Protean candidates.
08
Results
The central result is a family-level map rather than a claim about individual molecule function. The set contains broad family structure, a high singleton fraction, several recurring cysteine-spacing architectures, and a small number of cross-species families.
Comparison against experimentally characterized peptide space, represented here by the local DBAASP snapshot, found no exact or 90 percent identity candidate matches. Lower-identity nearest neighbors provide reference context, but do not support function transfer.
09
Discussion
The results suggest that psilocybin-producing fungal proteomes contain a broad computational landscape of short cysteine-rich, secreted-like peptide candidates. Family collapse matters because the original count of 470 candidates includes both singleton sequence hypotheses and larger repeated architectures.
The recurring motifs should be interpreted as sequence architectures. Some motifs recur across multiple families, but recurrence alone does not establish homology, secretion, activity, or ecological function. The strongest contribution of the campaign is a reproducible, artifact-backed prioritization surface for future review.
10
Limitations
Secretion status was treated as secreted-like based on deterministic sequence features and was not experimentally validated. Protein annotations, mature peptide boundaries, cysteine-rich filters, and family assignments are all computational and depend on the input assemblies and acquisition state.
Reference comparisons are local-archive bounded. The phrase unmatched means unmatched against the acquired local reference archive at the stated thresholds. It does not mean globally novel. DBAASP provides experimentally derived peptide context but does not establish activity, risk profile, or function for Protean candidates.
11
Reproducibility
The public study is backed by campaign manifests, Phase II validation artifacts, DBAASP snapshot verification, neighbor JSONL outputs, figure-generation scripts, and a public claims audit. Figure data are generated from the existing campaign outputs rather than synthetic or decorative data.
The publication build preserves the original discovery outputs. The website layer converts existing artifacts into public-safe narrative, figures, tables, metadata, and dynamic social images.
12
Data and Code Availability
The study page exposes public-safe figures, captions, tables, and source-artifact names. Raw campaign data and local database snapshots remain governed by the repository's publication boundary and are not automatically exposed through the website.
The source code for the publication page, content registry, figure export script, dynamic Open Graph image route, and claims audit is retained in the Protean repository for review.
13
Conclusion
Protean's Psilocybe Secretome Campaign moved from 470 computational mature peptide candidates to a family-level map of 346 cysteine-rich, secreted-like candidate families. The family structure, recurring motifs, cross-species families, and local reference-space distances provide a more defensible scientific view than candidate count alone.
The study's strongest claim is deliberately bounded: this is a reproducible computational survey and prioritization resource. It is not a validation study, not an activity claim, and not a therapeutic claim.
Figures
Publication figures from
existing artifacts.
figure 1 · campaign_manifest.json, phase2_validation_report.md
Study workflow

{kind=link}
figure 2 · candidate_statistics.json
Filtering funnel

{kind=link}
figure 3 · cluster_report.json
Cluster collapse

{kind=link}
figure 4 · candidate_statistics.json
Species contribution

{kind=link}
figure 5 · motif_analysis.json
Motif and family distribution

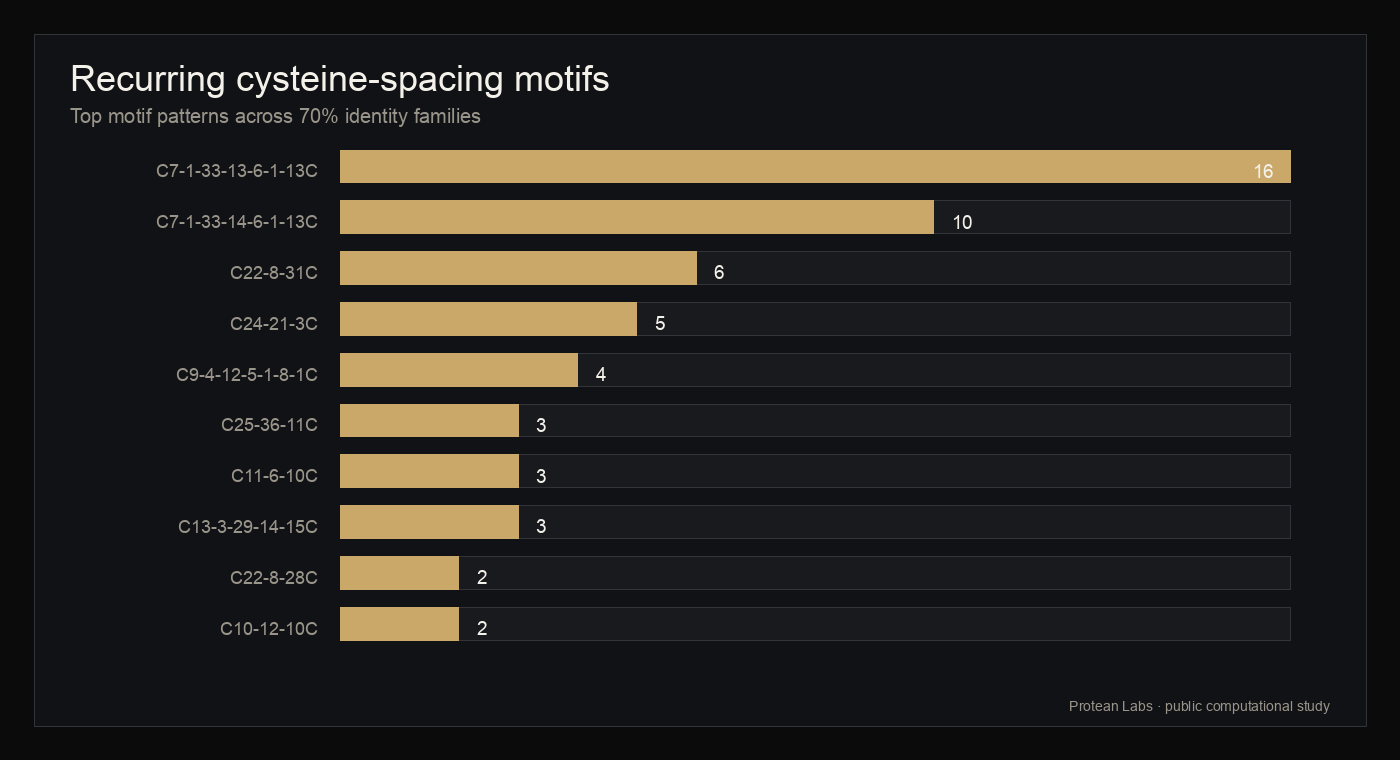{kind=link}
figure 6 · dbaasp_novelty_summary.json, dbaasp_candidate_neighbors.jsonl
DBAASP nearest-neighbor identity

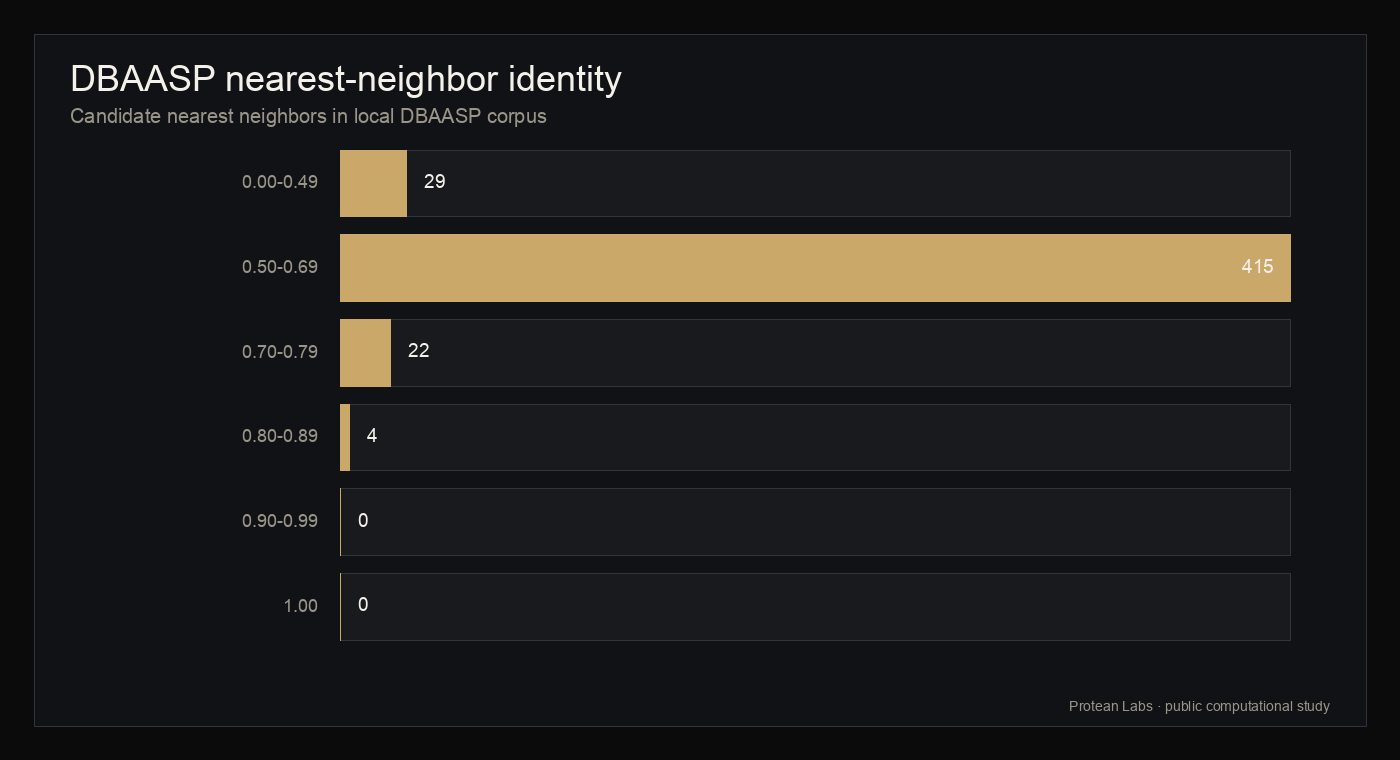{kind=link}
figure 7 · dbaasp_novelty_summary.json, novelty_report.json
Reference archive comparison

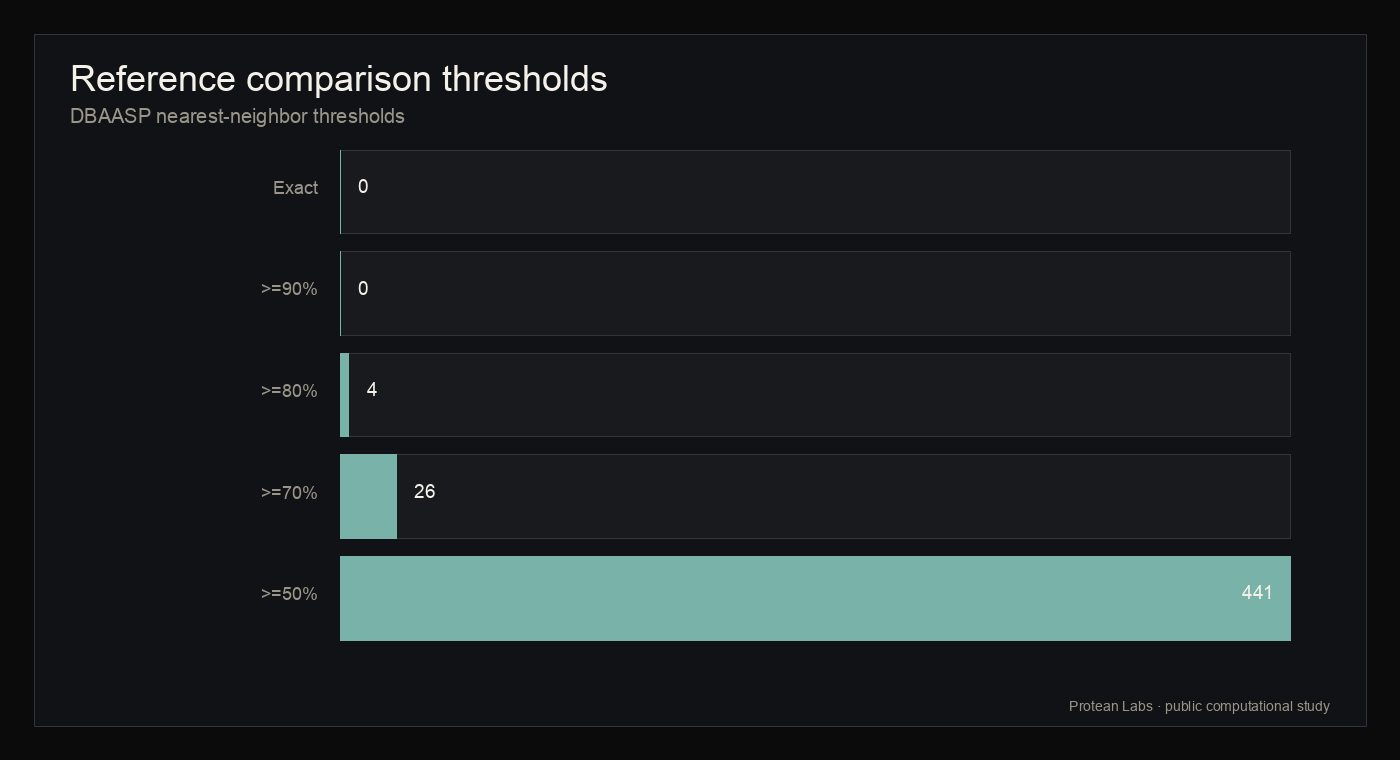{kind=link}
figure 8 · family_manifest.json, dbaasp_family_neighbors.jsonl
Top family representatives

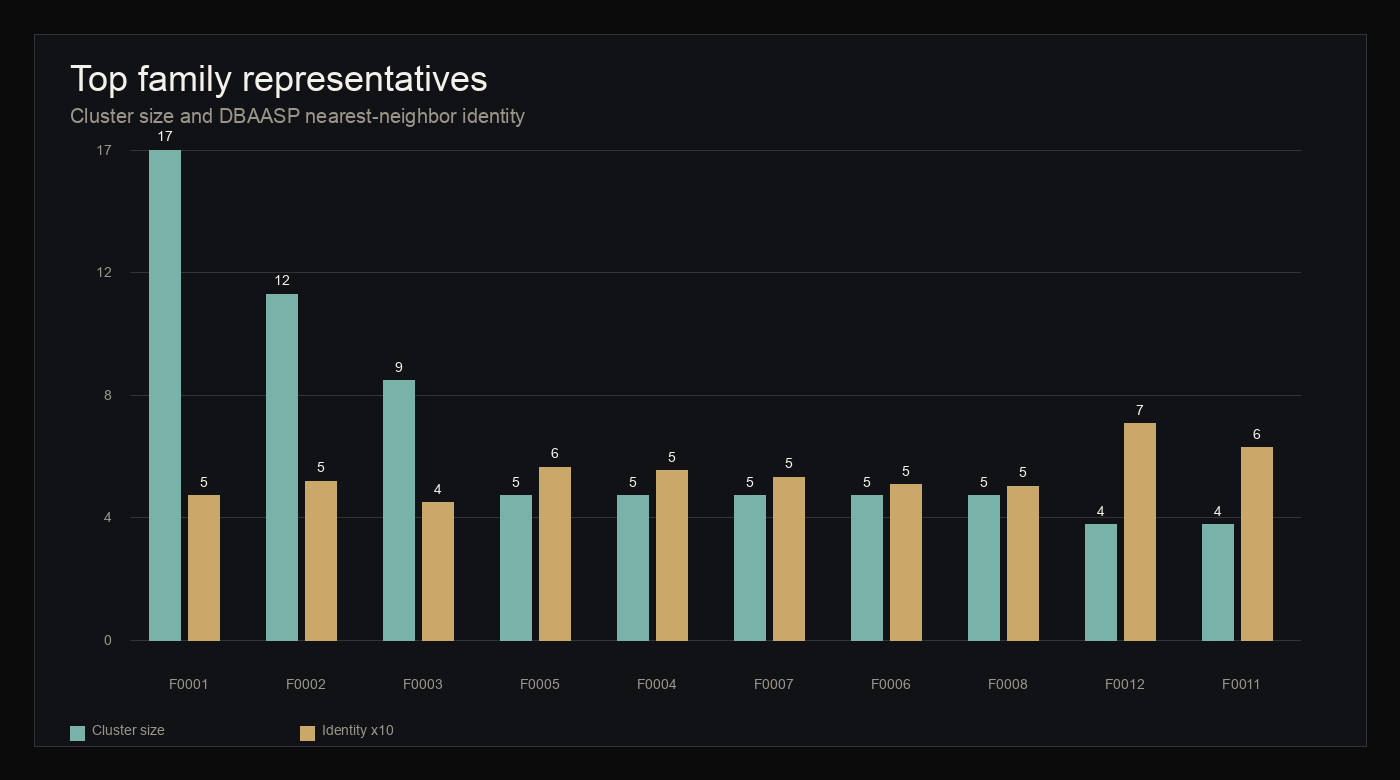{kind=link}
Tables
Counts, thresholds,
and boundaries.
Table · assemblies
Included and excluded assemblies
Assembly inclusion was determined during the original acquisition pass by availability of required NCBI protein FASTA, genomic GFF, and assembly report artifacts.
| Species | Assembly | Level | Source | Status |
|---|---|---|---|---|
| Psilocybe cubensis | GCF_017499595.1 MGC_Penvy_1 | Chromosome | RefSeq | Included |
| Psilocybe cyanescens | GCA_002938375.1 Psicy2 | Scaffold | GenBank | Included |
| Panaeolus cyanescens | GCA_002938355.1 ASM293835v1 | Scaffold | GenBank | Included |
| Gymnopilus dilepis | GCA_002938385.1 ASM293838v1 | Scaffold | GenBank | Included |
| Psilocybe azurescens | No selected assembly | n/a | NCBI | Excluded: no required protein FASTA plus genomic GFF package |
| Pluteus salicinus | No selected assembly | n/a | NCBI | Excluded: no required protein FASTA plus genomic GFF package |
Table · filtering funnel
Filtering funnel counts
Counts are taken from the completed campaign statistics and were not recomputed by the website build.
| Stage | Count | Interpretation |
|---|---|---|
| Predicted fungal proteins analyzed | 58449 | Input proteome records after acquisition and normalization |
| Small proteins <=150 amino acids | 8063 | Length screen |
| Secreted-like by deterministic sequence heuristic | 1394 | Signal-peptide-like feature screen |
| Cysteine-rich precursors | 1099 | Cysteine count or fraction screen |
| Mature peptide candidates | 470 | Mature candidate set |
| Unique mature peptide candidates | 470 | Global deduplication result |
Table · cluster summary
MMseqs2 cluster summary
MMseqs2 version 18-8cc5c was used for family collapse at 90, 80, and 70 percent identity.
| Identity threshold | Clusters | Singletons | Primary use |
|---|---|---|---|
| 90% | 442 | 415 | Near-duplicate collapse |
| 80% | 401 | 356 | Intermediate similarity view |
| 70% | 346 | 292 | Primary family definition |
Table · dbaasp snapshot
DBAASP snapshot summary
DBAASP was integrated as a local-first nearest-neighbor and reference-context corpus with no live scoring dependency.
| Snapshot field | Value | Boundary |
|---|---|---|
| Raw DBAASP records | 25069 | Local snapshot from dbaasp.org |
| Canonical normalized peptide rows | 20582 | Normalization output |
| Unique peptide sequences | 16989 | Reproducible unique count |
| Hydrated detail records present | 171 | Context where available |
| Scoring or ranking mutation | None | DBAASP was not used to change scores, ranks, or weights |
Table · dbaasp thresholds
DBAASP nearest-neighbor threshold summary
Threshold counts are candidate-level nearest-neighbor summaries across all 470 mature peptide candidates.
| Threshold | Candidate count | Interpretation |
|---|---|---|
| Exact DBAASP match | 0 | No exact sequence match in the local DBAASP snapshot |
| >=90% identity | 0 | No high-identity nearest neighbor at this threshold |
| >=80% identity | 4 | Small number of higher-similarity neighbors |
| >=70% identity | 26 | Lower high-similarity context |
| >=50% identity | 441 | Broad lower-identity neighbor context |
| Median nearest-neighbor identity | 0.5625 | Candidate-level median |
| Maximum nearest-neighbor identity | 0.875 | Candidate-level maximum |
Table · top 25 candidates
Top 25 Phase II candidates
Ranks are the existing Phase II prioritization output and were not modified for the public study page.
| Rank | Family | Candidate | Family size | Species | Phase II score | Novelty |
|---|---|---|---|---|---|---|
| 1 | mmseqs_70_0099 | psilocybe-secretome-gymnopilus-dilepis-7248e9bd | 1 | Gymnopilus dilepis:1 | 0.2903 | unmatched |
| 2 | mmseqs_70_0313 | psilocybe-secretome-psilocybe-cyanescens-a17435b5 | 1 | Psilocybe cyanescens:1 | 0.2779 | unmatched |
| 3 | mmseqs_70_0169 | psilocybe-secretome-panaeolus-cyanescens-62372ca7 | 1 | Panaeolus cyanescens:1 | 0.2717 | unmatched |
| 4 | mmseqs_70_0087 | psilocybe-secretome-gymnopilus-dilepis-55ea8408 | 1 | Gymnopilus dilepis:1 | 0.2559 | unmatched |
| 5 | mmseqs_70_0067 | psilocybe-secretome-gymnopilus-dilepis-249f6d4a | 1 | Gymnopilus dilepis:1 | 0.2457 | unmatched |
| 6 | mmseqs_70_0121 | psilocybe-secretome-gymnopilus-dilepis-bdc12010 | 1 | Gymnopilus dilepis:1 | 0.2389 | unmatched |
| 7 | mmseqs_70_0143 | psilocybe-secretome-gymnopilus-dilepis-f3c7cf8e | 1 | Gymnopilus dilepis:1 | 0.2347 | unmatched |
| 8 | mmseqs_70_0212 | psilocybe-secretome-psilocybe-cubensis-076256a3 | 1 | Psilocybe cubensis:1 | 0.2319 | unmatched |
| 9 | mmseqs_70_0265 | psilocybe-secretome-psilocybe-cyanescens-14143d99 | 1 | Psilocybe cyanescens:1 | 0.2315 | unmatched |
| 10 | mmseqs_70_0345 | psilocybe-secretome-psilocybe-cyanescens-f8b2d44c | 1 | Psilocybe cyanescens:1 | 0.2307 | unmatched |
| 11 | mmseqs_70_0064 | psilocybe-secretome-gymnopilus-dilepis-1185c2a6 | 1 | Gymnopilus dilepis:1 | 0.2289 | unmatched |
| 12 | mmseqs_70_0131 | psilocybe-secretome-gymnopilus-dilepis-d8070746 | 1 | Gymnopilus dilepis:1 | 0.2287 | unmatched |
| 13 | mmseqs_70_0250 | psilocybe-secretome-psilocybe-cubensis-c244b7e3 | 1 | Psilocybe cubensis:1 | 0.2262 | unmatched |
| 14 | mmseqs_70_0016 | psilocybe-secretome-panaeolus-cyanescens-3c0b6230 | 3 | Panaeolus cyanescens:3 | 0.2228 | unmatched |
| 15 | mmseqs_70_0332 | psilocybe-secretome-psilocybe-cyanescens-dbacbc9a | 1 | Psilocybe cyanescens:1 | 0.2212 | unmatched |
| 16 | mmseqs_70_0153 | psilocybe-secretome-panaeolus-cyanescens-14669d14 | 1 | Panaeolus cyanescens:1 | 0.2186 | unmatched |
| 17 | mmseqs_70_0053 | psilocybe-secretome-psilocybe-cyanescens-a2f0ebce | 2 | Psilocybe cyanescens:1, Psilocybe cubensis:1 | 0.2181 | unmatched |
| 18 | mmseqs_70_0055 | psilocybe-secretome-gymnopilus-dilepis-00fd0ecb | 1 | Gymnopilus dilepis:1 | 0.2162 | unmatched |
| 19 | mmseqs_70_0278 | psilocybe-secretome-psilocybe-cyanescens-36a5a4ea | 1 | Psilocybe cyanescens:1 | 0.2099 | unmatched |
| 20 | mmseqs_70_0310 | psilocybe-secretome-psilocybe-cyanescens-94a830d9 | 1 | Psilocybe cyanescens:1 | 0.2099 | unmatched |
| 21 | mmseqs_70_0199 | psilocybe-secretome-panaeolus-cyanescens-d1d9dd38 | 1 | Panaeolus cyanescens:1 | 0.2063 | unmatched |
| 22 | mmseqs_70_0083 | psilocybe-secretome-gymnopilus-dilepis-4a527cb2 | 1 | Gymnopilus dilepis:1 | 0.2054 | unmatched |
| 23 | mmseqs_70_0324 | psilocybe-secretome-psilocybe-cyanescens-bfbac08d | 1 | Psilocybe cyanescens:1 | 0.2033 | unmatched |
| 24 | mmseqs_70_0056 | psilocybe-secretome-gymnopilus-dilepis-04232462 | 1 | Gymnopilus dilepis:1 | 0.2017 | unmatched |
| 25 | mmseqs_70_0222 | psilocybe-secretome-psilocybe-cubensis-29265e62 | 1 | Psilocybe cubensis:1 | 0.2006 | unmatched |
Table · top 10 families
Top 10 largest family representatives
Representatives are the largest 70 percent identity families. DBAASP values are nearest-neighbor context only.
| Family | Representative candidate | Size | Species distribution | Motif | DBAASP identity | Coverage |
|---|---|---|---|---|---|---|
| mmseqs_70_0001 | psilocybe-secretome-panaeolus-cyanescens-4483cb77 | 17 | Gymnopilus dilepis:3; Panaeolus cyanescens:2; Psilocybe cubensis:6; Psilocybe cyanescens:6 | C7-1-33-13-6-1-13C | 0.5000 | 0.2917 |
| mmseqs_70_0002 | psilocybe-secretome-psilocybe-cyanescens-35b32b4b | 12 | Gymnopilus dilepis:2; Psilocybe cubensis:3; Psilocybe cyanescens:7 | C15-32-14C | 0.5500 | 0.2174 |
| mmseqs_70_0003 | psilocybe-secretome-panaeolus-cyanescens-e50cec72 | 9 | Gymnopilus dilepis:1; Panaeolus cyanescens:8 | C7-1-33-14-6-1-13C | 0.4762 | 0.2247 |
| mmseqs_70_0004 | psilocybe-secretome-panaeolus-cyanescens-5e0f6256 | 5 | Panaeolus cyanescens:5 | C7-1-33-13-6-1-13C | 0.5882 | 0.1932 |
| mmseqs_70_0005 | psilocybe-secretome-panaeolus-cyanescens-73d40076 | 5 | Panaeolus cyanescens:5 | C1-4-10-21-7C | 0.6000 | 0.1705 |
| mmseqs_70_0006 | psilocybe-secretome-psilocybe-cubensis-4600dcef | 5 | Psilocybe cubensis:3; Psilocybe cyanescens:2 | C22-8-28C | 0.5385 | 0.2308 |
| mmseqs_70_0007 | psilocybe-secretome-psilocybe-cubensis-901c7b27 | 5 | Psilocybe cubensis:3; Psilocybe cyanescens:2 | C7-1-33-13-6-1-13C | 0.5652 | 0.2556 |
| mmseqs_70_0008 | psilocybe-secretome-psilocybe-cyanescens-518db899 | 5 | Psilocybe cyanescens:5 | C8-10-25-8-40C | 0.5333 | 0.1271 |
| mmseqs_70_0009 | psilocybe-secretome-gymnopilus-dilepis-17ecf577 | 4 | Gymnopilus dilepis:4 | C7-10-25-8-40C | 0.5294 | 0.1518 |
| mmseqs_70_0010 | psilocybe-secretome-gymnopilus-dilepis-bae12773 | 4 | Gymnopilus dilepis:1; Panaeolus cyanescens:1; Psilocybe cubensis:1; Psilocybe cyanescens:1 | C10-11-3-5-11-6C | 0.5625 | 0.1923 |
Table · limitations
Limitations and unresolved validation steps
These limitations are part of the public claim boundary and should be read with the results.
| Topic | Current status | Conservative public wording |
|---|---|---|
| Secretion/localization | Deterministic sequence features only | Secreted-like; not experimentally localized |
| Biological function | Not assayed | No activity or molecular function is claimed |
| Toxicity or risk profile | Not assayed for Protean candidates | Nearest-neighbor annotations are context only |
| Reference archive scope | Local acquired archive | Unmatched against the acquired local reference archive, not globally novel |
| Assembly and annotation dependence | NCBI assembly-dependent | Candidate set depends on available predicted proteomes and annotations |
| Ranking | Existing scores and ranks retained | DBAASP and publication work did not modify scores, ranks, or weights |
Artifacts
Public links and
background sources.
Public-safe artifacts
- Figure manifest
Public-safe figure captions, alt text, and source artifact names.
- Filtering funnel SVG
Vector figure generated from candidate_statistics.json.
- DBAASP identity distribution SVG
Vector figure generated from dbaasp_novelty_summary.json.
Background sources
- DBAASP
Background source identifying DBAASP as a peptide reference database; Protean results use local snapshot artifacts as the data source.
- NCBI article used for style orientation
Used only to orient formal article structure and review-paper depth, not to supply campaign results.
- Psilocybin biosynthesis context
Background context for fungal lineages; not a source for Protean campaign counts.
- Next.js Open Graph image file convention
Implementation reference for dynamic study social images.