Protean Labs: a scientific operating system for autonomous peptide discovery.
Most AI-bio projects compress the entire pipeline into prompt → molecule. Protean Labs is built differently. Galen is the operating agent layer. Base mainnet is the provenance ledger. x402 is the programmable wet-lab payment rail. $PRTN is the infrastructure layer beneath all of it. This is the long-form introduction to how the pieces fit together.
The problem
Why prompt → molecule isn't science.
A typical AI-bio demo looks like this. A user types a target name. A model emits a peptide sequence. A pretty chart appears. Someone tweets it. There is no evidence trail, no reproducible cycle, no failure memory, no audit log of what the system actually considered, and no mechanism connecting the generated string to the wet-lab work that would have to follow.
Real scientific discovery is not a one-shot prompt. It is a loop: evidence is ingested, hypotheses are formed and tested, candidate families are generated under explicit constraints, deterministic validators reject the weak ones, multi-axis ranking prioritizes the rest, explanations are checked against evidence, plans are written, top candidates move into wet-lab review, results come back, and the loop tightens. Every step has provenance. Every artifact has a hash.
What this is
What Protean Labs is building.
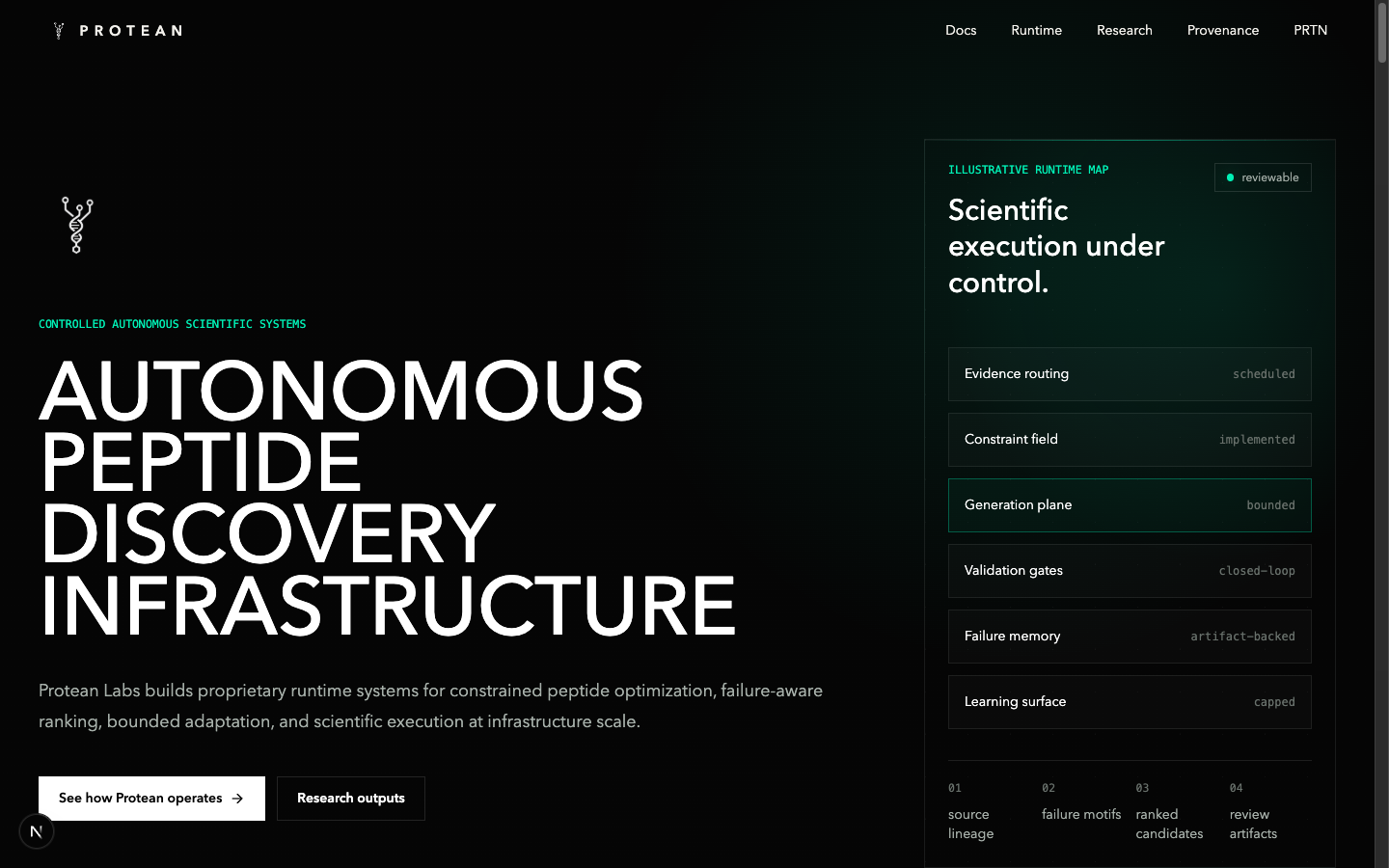
Protean Labs is an autonomous scientific operating system for peptide discovery. It is local-first by default, provenance-aware by design, and structured around scientific objects rather than free-form text. Each full cycle produces an immutable manifest with SHA-256 hashes over every artifact it produced, a redacted public provenance graph, deterministic object and edge identifiers, and a sealed cycle directory that can be replayed bit-for-bit by anyone with the public bundle.
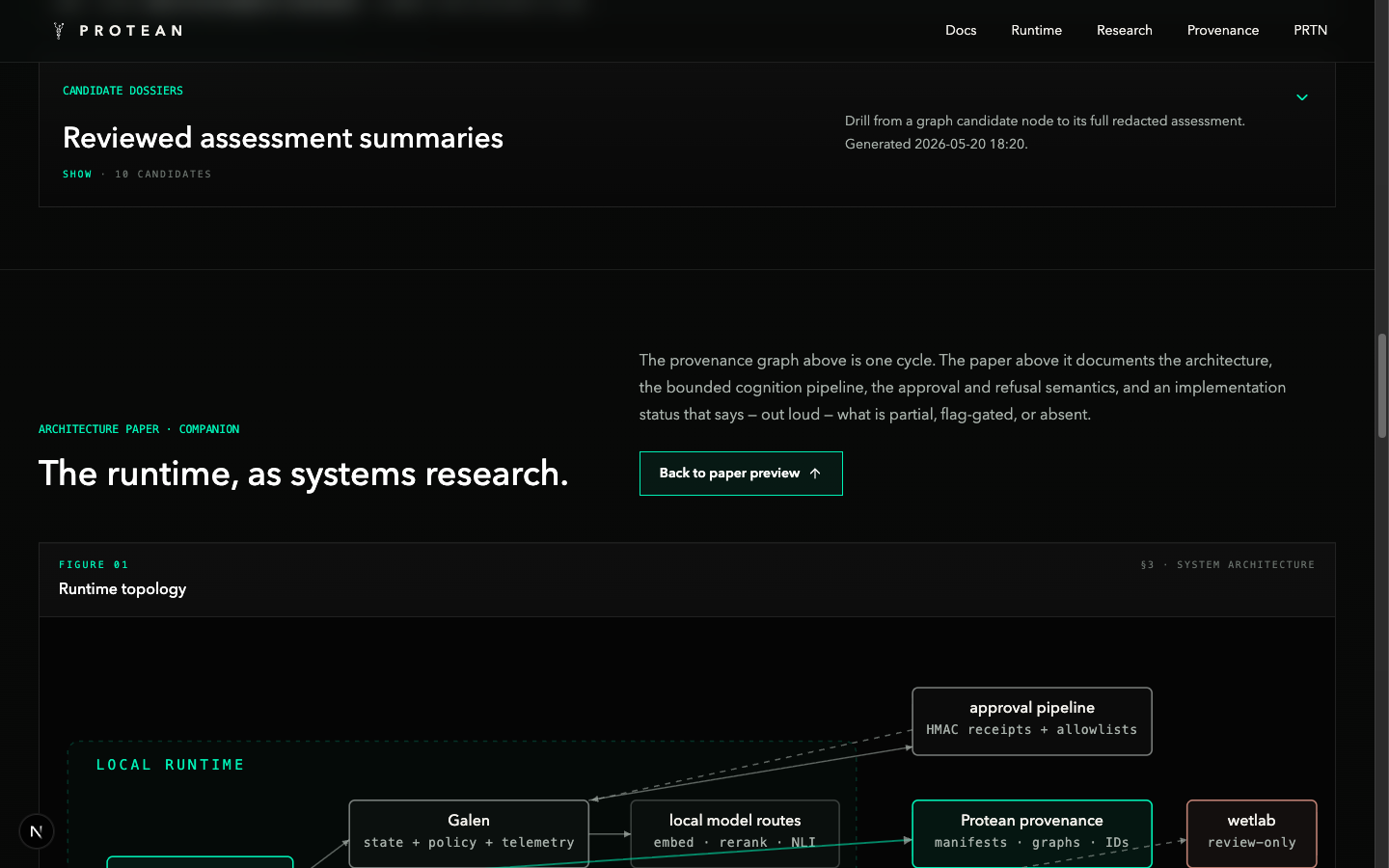
The runtime ships today as three layered pieces. The first is a continuous cognition loop that ingests evidence, parses it into structured scientific memory, generates and ranks candidate families, runs claim QA against local evidence, builds the public provenance graph, and seals each cycle into a replayable snapshot. The second is Galen, an external operational supervisor built on the OpenClaw agent runtime. The third is the canonical Protean Registry contract on Base mainnet — the provenance commitment layer that turns "we ran a cycle" into "this is the cryptographically anchored cycle, here is the tx."
The agent layer
Galen: the OpenClaw operating agent.
Galen is the active operational layer of Protean. It is not a chatbot, not an oracle, and not the scientific runtime itself. Galen is an OpenClaw agent identity — a single persona reachable over a single-operator Telegram channel — wrapped around a deterministic ingestion pipeline, a set of bounded observer scripts, and a growing cognition kernel.
Earlier internal docs framed this layer as "Hermes." That framing has been replaced. Galen is the canonical agent name, the operational supervisor for the Protean scientific kernel, and the only system path authorized to ingest external URLs, register cron jobs, and surface anomalies to the operator. Galen does not score peptides, does not mutate validators, does not commit code to the Protean repo, and never publishes raw sequences. The boundary contract lives in~/galen/BOUNDARIES.md and is enforced primarily through persona prompting plus architectural reach — the ingestion adapter cannot import scoring modules; the public-boundary audit cron job runs every six hours and alerts on any leakage.
What Galen actually does today, on disk:
- Runs 12 self-built scheduled jobs covering Protean health watch (every 30m), public-boundary audit (every 6h), daily ops brief (09:00), memory maintenance (every 3 days), cycle anomaly detection, provider health, capability-graph growth summaries, and several others. Each job is a fresh isolated agent session with an embedded scope-bounded prompt — no shared in-process state.
- Owns a five-stage deterministic ingestion pipeline (parse, canonicalize, enrich, trust-score, store) that lands external signals into Protean's external-signals inbox via a single MCP tool. Protean-side schema rejects any payload that references scoring or prompt code by name.
- Maintains a read-only mirror of Protean's scientific state — hypotheses, contradictions, assay gaps, cycle health — so it can reason about and report on the science without owning it.
- Sends operational telemetry to one allowlisted Telegram channel. The Telegram surface is observability and control, not scientific authority. Galen never publishes claims; it surfaces anomalies and waits for human review.
The scientific loop
From evidence to candidate families.
A candidate is not a free-form generation. It is the output of a constrained optimization process. The runtime retrieves relevant evidence from a local SQLite + embeddings index, parses it into structured scientific memory (motifs, cleavage patterns, degradation signals, permeability references, stability relationships, failure correlations, assay outcomes, sequence relationships, contradiction signals), then uses that memory to shape the search.
Generation proposes; deterministic validators decide. Each candidate is evaluated against protease resistance, cleavage risk, motif redundancy, failure similarity, stable motif similarity, novelty, synthesis plausibility, sequence-space neighborhood, embedding-space position, collection fit, and downstream assay readiness. LLMs are proposal and synthesis tools, not the source of truth. Deterministic validators, scoring systems, retrieval layers, lineage records, and the scientific object graph remain authoritative.
The model stack reflects this. ESM-2 for peptide sequence embeddings, BGE-M3 for evidence retrieval, BGE-reranker for ranking retrieved evidence, ModernBERT-NLI for claim checking, local Qwen / MLX models for reasoning and explanation. Different models for different jobs. The core runtime is local-first because raw sequences, unfiled IP, and internal scientific memory are sensitive — they don't leave the machine.
Object model
Scientific objects and collections.
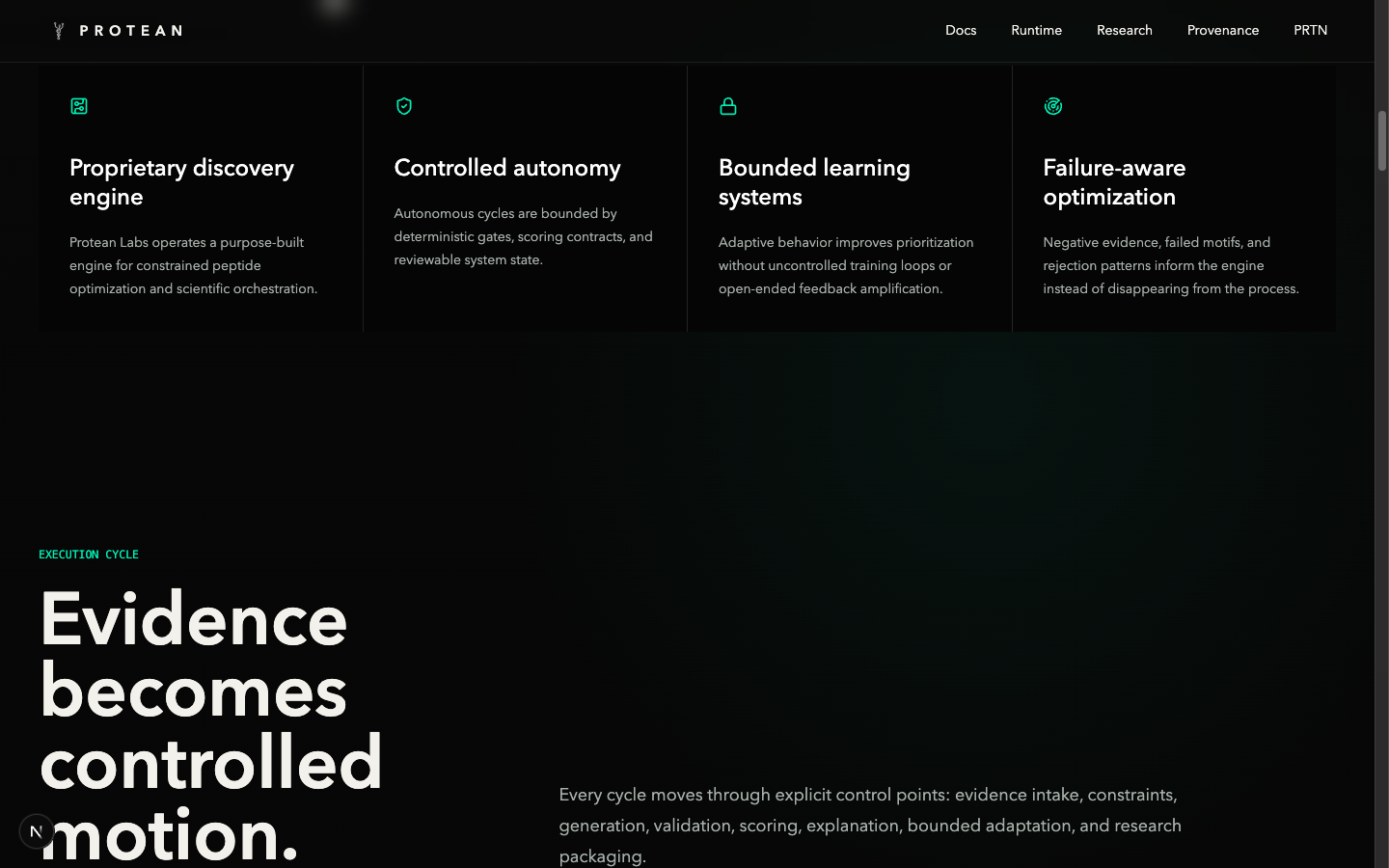
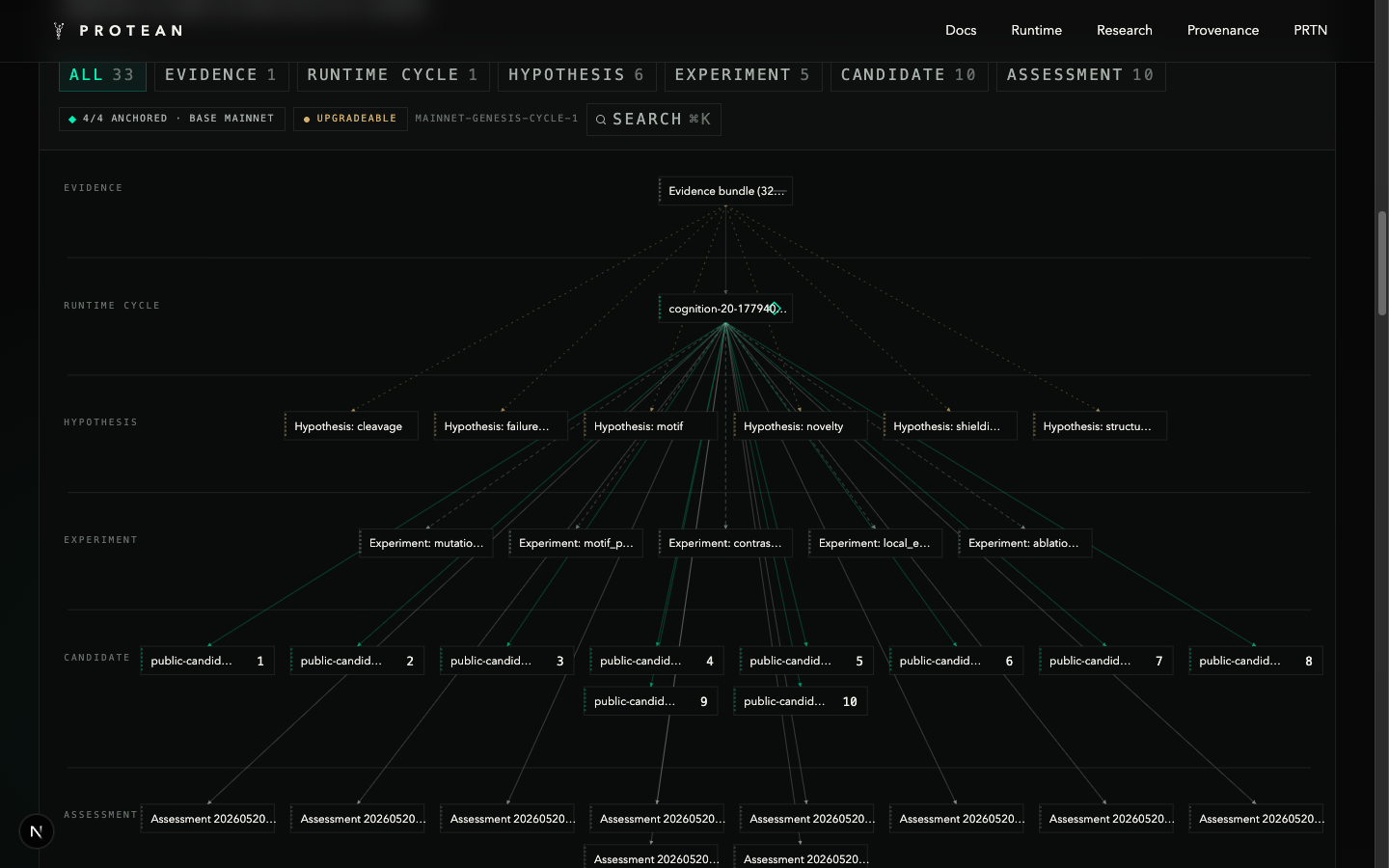
Inside Protean, a candidate is not a row in a spreadsheet. It is a typed scientific object with lineage, evidence, rank history, explanation history, collection membership, paper artifacts, provenance references, assay state, and review status. The same is true for hypotheses, experiments, candidate families, evidence bundles, assay requests, assay results, papers, runtime cycles, and provenance records.
The canonical contract ontology covers 28 object types and 18 relation types — the union of every state the system ever needs to represent. The wet-lab track (assay requests, assay batches, assay results, wet-lab providers, provider packets, quote reviews, payment intents) and the IP track (IP disclosures, patent filings, public releases) sit alongside the cognition track (hypotheses, experiments, capability artifacts, scientific-memory snapshots) and the governance trail (approval receipts, review records). Lifecycle states progress strictly forward — Draft → ReviewReady → Anchored → AssayRequested → AssayReturned → IPReview → PatentFiled → Published — with terminal states (Superseded, Disputed) and no backward transitions.
Collections are the cohort layer. A collection might represent "Protease Stability Batch 001" or "Oral Delivery Exploration Set" or "Cleavage Resistance Study." A collection can carry candidate families, experiments, papers, hypotheses, assay results, lineage graphs, and provenance records. The long-term value is rarely one peptide in isolation. It is the structured scientific state around it: validation history, benchmark data, failure data, assay lineage, reproducibility, provenance. That is what collections are for, and what the network will be interesting around.
Public surface
What the website actually shows.
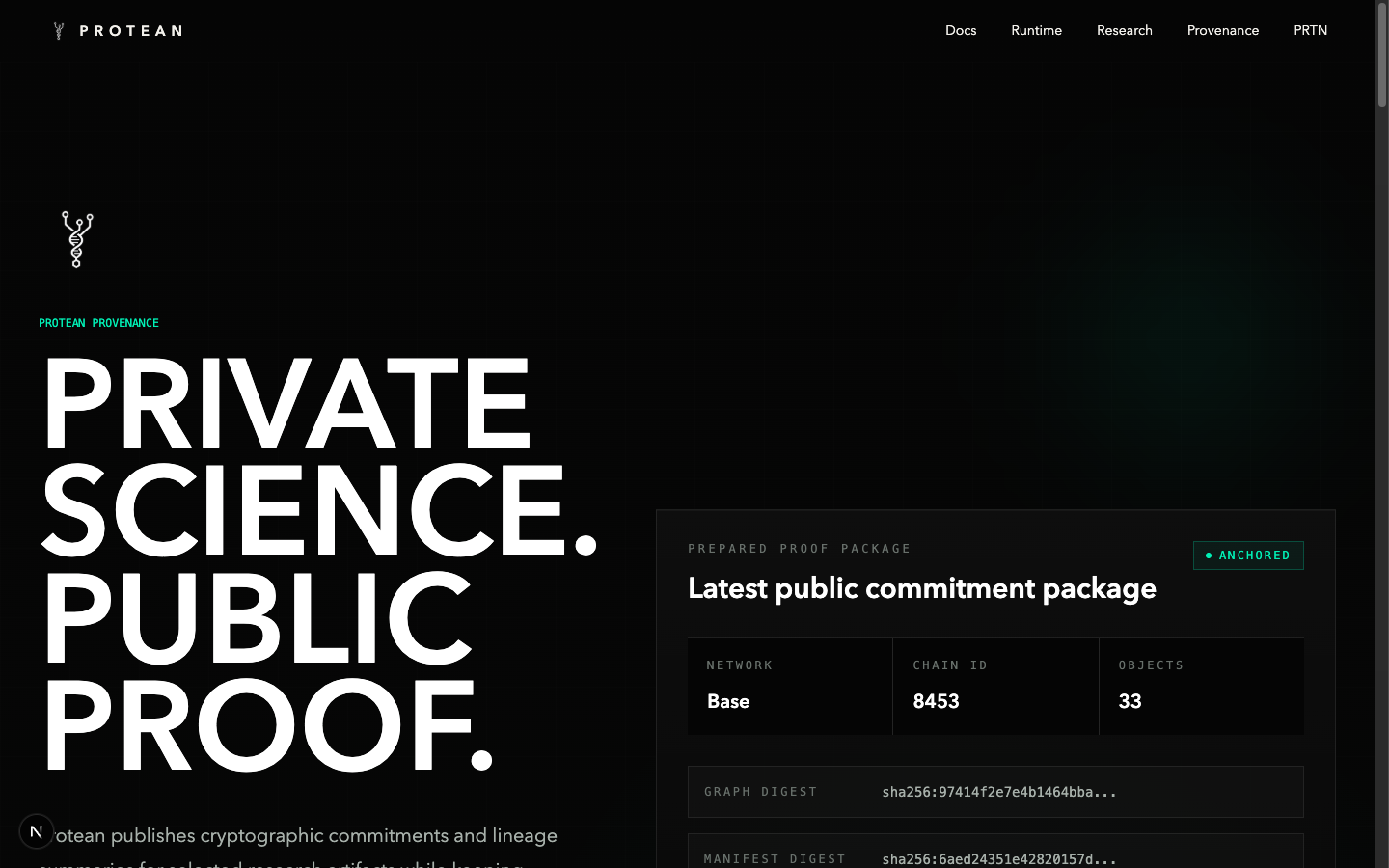
Everything user-facing on protean.sh is a redacted view of real runtime state. The homepage proof strip reads live numbers from three sources: cycle manifests under data/cycles/, the redacted public graph under public/export/provenance/, and the on-chain anchored state under public/export/onchain/. The "ONCHAIN ANCHOR" card on the homepage reflects the live Base mainnet anchor — proxy address, anchor transaction hash, objects verified on chain, freeze status.
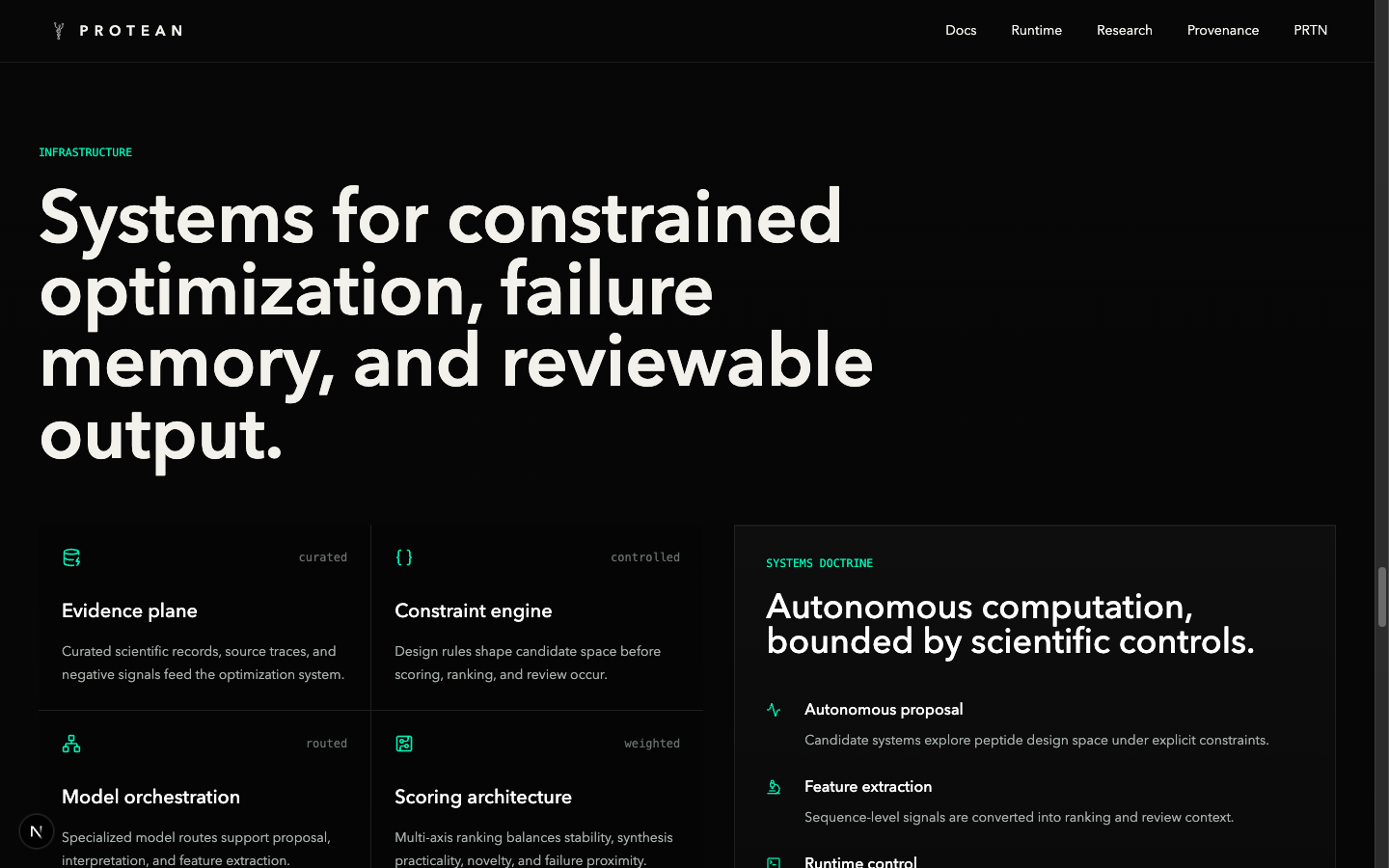
/research is the live provenance graph for the most recent runtime cycle. Nodes are typed (candidate, hypothesis, experiment, evidence bundle, paper, runtime cycle); edges are typed lineage relationships. Each node is content-addressed; per-object on-chain verification badges resolve through the canonical proxy. The architecture paper is embedded inline at the top of the page so it can be read without leaving the site.
/provenance is the boundary statement page — private science, public proof. /docs covers the runtime architecture, the cognition pipeline, Galen operations, the discovery lifecycle, the provenance layer, and the roadmap.
Architecture paper
The Protean & Galen paper.
The architecture paper documents the runtime in detail: cycle structure, manifest model, public-private graph boundary, lifecycle state machine, cognition pipeline, peptide workflow, runtime safety, and an explicit implementation status table that names what is implemented, partial, flag-gated, review-only, or absent. It also includes eight reproducible figures and a companion artifact bundle that lets a reviewer replay the manifest hashing and graph invariants from a redacted snapshot.
One thing worth saying out loud: the paper does not claim biological validation, validated receptor binding, PK/PD prediction, toxicology, or efficacy. It claims an auditable runtime pattern — a reproducible systems invariant for AI-assisted scientific cognition with replayable evidence lineage and review gates. That distinction is the whole point.
Base provenance
The contracts on Base mainnet.
The Protean contract on Base is not an NFT for peptides. It is a provenance and coordination registry. The on-chain surface stores commitments and pointers only — content hashes, lineage hashes, location hashes, salted candidate commitments, lifecycle state, disclosure state, and runtime-cycle anchors. Raw sequences, salts, scoring internals, embeddings, and unfiled IP stay offchain in the private vault. The chain stores existence, timing, and integrity. It does not store secrets.
The authority model splits operational from governance. The runtime/operator wallet holds four scoped roles: registering scientific objects, linking and revoking lineage edges, writing commitment updates, and emitting CycleAnchored events. The treasury wallet — proteanlabs.base.eth — holds DEFAULT_ADMIN_ROLE, UPGRADER_ROLE, and PAUSER_ROLE. The operator wallet cannot upgrade the contract, cannot grant roles, and cannot pause. That separation is enforced on chain by OpenZeppelin AccessControl and verified adversarially in the test suite (30 / 30 passing).
What this buys the network: a candidate, paper, experiment, or collection can be anchored at a specific time without exposing the underlying sequence, and indexers can deterministically reconstruct the public scientific object graph from event logs. The cryptographic identity surface is shared by an offline Python utility (17 / 17 passing) so the on-chain IDs match exactly what the runtime computes locally.
Wet-lab payments
x402 as the programmable wet-lab payment rail.
Computational candidates are research-prioritization signals, not therapies. The next step is connecting them to wet-lab execution in a way that is auditable and eventually automatable. The shape of that connection: Galen selects a candidate cohort; the runtime prepares an assay request packet with redacted provider-safe metadata; a wet-lab provider exposes a paid service endpoint; payment is authorized through x402-style rails; and the request, payment, artifact hash, and later result hash are linked into the public provenance graph as typed edges (PaysFor, ResultOf, Includes).
The right mental model for crypto-native readers: x402 is the payment layer for machine-requested services. The canonical Protean Registry on Base is the audit layer. Galen is the scientific runtime and operator supervisor. Wet labs are the execution layer. Programmable wet-lab providers like Adaptyv are where the execution path lands; Protean acts as the cognition + orchestration + provenance layer that prepares, commits, pays, and verifies.
Funding the loop
How Bankr trading fees help fund wet-lab handoffs.
$PRTN is launching via Bankr. The intended funding model is not speculative — it is operational. Trading fees from the Bankr launch are intended to be routed toward real scientific execution: paying for assays, paying providers, funding synthesis, and covering the on-chain anchoring of wet-lab cycles. The token market activity creates a funding stream; that stream goes toward the next step of the scientific loop.
The combination of x402 (programmable payment), Bankr trading fees (funding stream), and Base provenance (audit layer) is what makes the loop possible to operate transparently. Every wet-lab request has a payment trace, every payment has an on-chain commitment, every commitment is hashable and replayable. Nothing about that requires $PRTN to be anything more than the infrastructure layer under the network.
The token
Where $PRTN actually sits.
$PRTN is positioned as the infrastructure layer underneath the Protean scientific network. Not a governance token. Not a royalty ledger. Not biotech equity. The token sits beneath provenance anchoring, collections, scientific object graphs, runtime access, orchestration workflows, public artifact publication, wet-lab coordination, and future network-aligned participation. The increase in value, if any, is intended to track the increase in load-bearing scientific workflows flowing through the network — not a one-shot drug discovery story.
Future participation
ACE-style participation as a possible compliant path.
One open design question for any scientific network: if discoveries or collections become commercially meaningful, how do network participants align without reckless promises? Protean is preserving optionality on this, not committing to a mechanism. One possible future shape is an ACE-style structure — an Asset-Conditional Exchange — where eligible $PRTN holders could potentially exchange tokens for compliant equity or participation in a separate vehicle tied to a specific scientific initiative.
That is not how $PRTN works today. $PRTN today is the infrastructure layer; ACE-style mechanisms, if pursued, would be entirely separate structures with their own legal review, eligibility checks, and compliance work. The strategic preservation is the optionality, not a roadmap commitment. Nothing in this paragraph constitutes an offer.
Roadmap
What ships next.
The honest implementation map, with shipping line:
- Shipped: cycle runner, immutable cycle snapshots, public provenance graph (V2 schema), candidate generation, ranking, claim QA, scientific memory consolidation, redaction guard, HMAC approval pipeline, canonical Protean Registry live on Base mainnet with RBAC + treasury handoff, the architecture paper, Galen's 12 cron jobs and ingestion pipeline.
- In progress: Galen's continuous cognition kernel (hybrid frame, three-tier router); migration from purely interval execution to a daily ingestion loop plus bounded continuous research and memory consolidation; contradiction graph materialization as a default loop stage; workflow DAG per-step enforcement; expanded telemetry surface.
- Roadmap: simulated wet-lab dry run; real provider adapter (likely Adaptyv first); x402 payment integration tied into the provenance graph; collection-evolution memory; lifecycle transitions with append-only history; explicit future review of any compliant ACE-style participation structure.
- Intentionally not on the roadmap: autonomous wet-lab submission without operator review; raw sequence publication; any mutation of scoring or validators by Galen or by the runtime itself; token-holder rights to specific peptide IP.
Why it matters
Scientific infrastructure that can think, test, remember, and prove.
The interesting bet is not "AI will write a great peptide." The interesting bet is that scientific infrastructure becomes more valuable than any one molecule when it can reason continuously, retain failure-aware memory, anchor public provenance, prepare programmable wet-lab handoffs, and replay every step deterministically from a sealed snapshot. That is the kind of system that compounds, and that is what Protean Labs is building.
None of this requires anyone to take a biological claim on faith. The paper, the contracts, the manifests, and the public provenance graph are all in the open. The token is the infrastructure layer under that network. The wet lab is the eventual truth-check downstream. The agent is bounded, the runtime is local-first, the audit is on Base.